
I’m a computer science graduate student at the University of Pennsylvania  , working on Large Language Models (LLMs), Vision-Language Models (VLMs), and NLP applications in AI for Science.
, working on Large Language Models (LLMs), Vision-Language Models (VLMs), and NLP applications in AI for Science.
At Penn, I’m fortunate to be advised by Prof. Chris Callison-Burch, Prof. Lyle Ungar, and Delip Rao. I also collaborate with Dr. Xiaodong Yu (AMD GenAI) and Prof. Yunhuai Liu (Peking University).
My research centers on advancing (M)LLMs with Effective, Efficient, and Explainable methods. I care about building models that work better, run cheaper, and fail more predictably. Just as importantly, I want to understand why they work, when they break, and how we can steer them with confidence.
Today, a lot of progress comes from large-scale training and black-box iteration. It works, but it often hides the reasons behind progress and makes reliability harder to reason about. At the same time, scaling alone is starting to feel more incremental. That’s why I focus on two complementary directions:
From understanding → to reliable impact → to continual improvement
-
1. Mechanism-driven Understanding (Interpretability + optimization): I study what is happening inside LLMs and VLMs, and how those internal signals can be used to improve models. I look at attention patterns, residual streams, activations, representations, and logits. My goal is not interpretability as a visualization layer. My goal is interpretability that changes how we optimize and control models.
(More: Why I care about interpretability) -
2. Model Adaptation (From base models to real experts): I work on adapting foundation models to specific domains and building systems with measurable impact. I'm interested in task-agnostic adaptation pipelines where we can inject real scientific novelty, including post-training (SFT, RL, distillation), efficiency methods (quantization, pruning, layer skipping, routing), and system-level tooling like retrieval and evaluation. I also like going deep into real domains, where novelty often comes from new tasks, synthetic data, and sometimes further architecture optimization.
(More: Why I care about model adaptation)
I am also the co-founder of Savable Koupon AI, where we build AI-driven price tracking, LLM-based product analysis, and recommendation systems for e-commerce. I serve as a reviewer for top-tier conferences like ICLR, ACL, CVPR, AAAI.
You can find my publications on Google Scholar
🔥 News
- November 2025: 🎉 One first-author paper and one single-author paper accepted to AAAI 2026
- July 2025: 🎉 First-authored paper accepted to COLM 2025
- June 2025: 🎉 Paper published in Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) 2025
- June 2025: 🎉 First-authored paper accepted to MOSS@ICML2025
Why I’m excited about these problems
Why I care about interpretability
Interpretability, for me, begins with curiosity. I like watching a system and asking: why did that happen? It feels like being a kid observing insects. You stare long enough, and suddenly a pattern shows up. That moment of “wait, that’s weird” makes me happy.
More rationally, interpretability also serves a long-term goal: building AI systems that are truly reliable, possibly all the way to AGI or even ASI.
- If scaling eventually leads to AGI, we may get extremely capable black-box systems. Then the key question becomes safety and alignment. How do we ensure a superintelligent model consistently acts in good faith, and does not quietly deceive people to do harm?
- If scaling alone still fails to reach AGI, we will need deeper answers. Why do these models work at all? What factors truly drive their performance?
Good explanations help us trust models in practice. They also guide us to design better models based on principles, not just trial and error.
I often think about how physics matured. First came careful observations (Tycho Brahe). Then hypotheses (Kepler). Then principles (Newton). In AI, we have made huge empirical progress, many interpretability papers open a trained model and hunt for circuits. I love and respect that line of work, such as logit-lens analyses for LLMs/VLMs, sparse autoencoders (SAEs), and recent mechanistic interpretability work from Anthropic. But we still lack “Newton-style” first principles.
I want to ask questions that begin at the level of training processes and model architecture.
Why do compositional features and circuits appear at all? Why do we sometimes see sparsity, low-rank structure, or neatly separated factors after training? Can we connect those outcomes to the equations of gradient-based learning, instead of only collecting evidence after the fact?
For example, I like the ICLR 2025 oral paper Learning Dynamics of LLM Finetuning, which offers explanations for why SFT can lead to hallucinations and why DPO performance may degrade over time.
My hope is that interpretability can slowly move from biology-style observation to physics-style reasoning. If that shift happens, it will feel like a real change of era.
Why I care about model adaptation
I also spend a lot of energy thinking about adaptation. Partly because I do not believe “general” intelligence comes for free.
Scaling has worked, but the returns can slow down. It is unlikely that every new GPT-n will feel as shocking as the earlier jump from GPT-4. At the same time, we have already had LLMs in the real world for several years, but there are still many specialized tasks they cannot do well. Pretraining will never perfectly cover every niche, every workflow, or every kind of expertise.
So I care about a practical question. How do we turn a strong base model into a model that is genuinely useful for a specific need?
I think about this in two layers.
First, I want to improve the general “base-to-expert” pipeline. That includes post-training methods like SFT, RL, and distillation. It also includes inference efficiency, such as quantization, pruning, layer skipping, and routing. I also care about retrieval, evaluation, and benchmarks, because the workflow around a model often matters as much as the model itself.
Second, I want to take these tools into real domains and make them work end-to-end. This idea is not new. It was central in the BERT era, and it is still central now. Beyond popular areas like coding and document analysis, I think many domains that rely on careful human judgment could benefit from LLM-based specialists. Malware or virus detection is one example.
Some people see this direction as just engineering (data+training). But I am drawn to it because I believe engineering can carry real scientific novelty.
Sometimes the novelty is how you get data when data is scarce. Sometimes it is how you design synthetic data that teaches the right behavior. Sometimes it is how you change representations or architectures when the base model cannot capture a key dependency. Sometimes it is how a new industrial need becomes a new research question.
In the long run, I am optimistic about a system view of intelligence. If we can build many strong, efficient specialists, and let them collaborate as agents, we may reach broad capability in a way that is easier to maintain, easier to adapt, and easier to interpret than betting everything on a single monolithic model.
📝 Selected Publications
For a complete list of publications, please visit my Google Scholar
🔮 Research Interest 1: Uncovering NLP & LLM Internal Mechanism and Interpretability
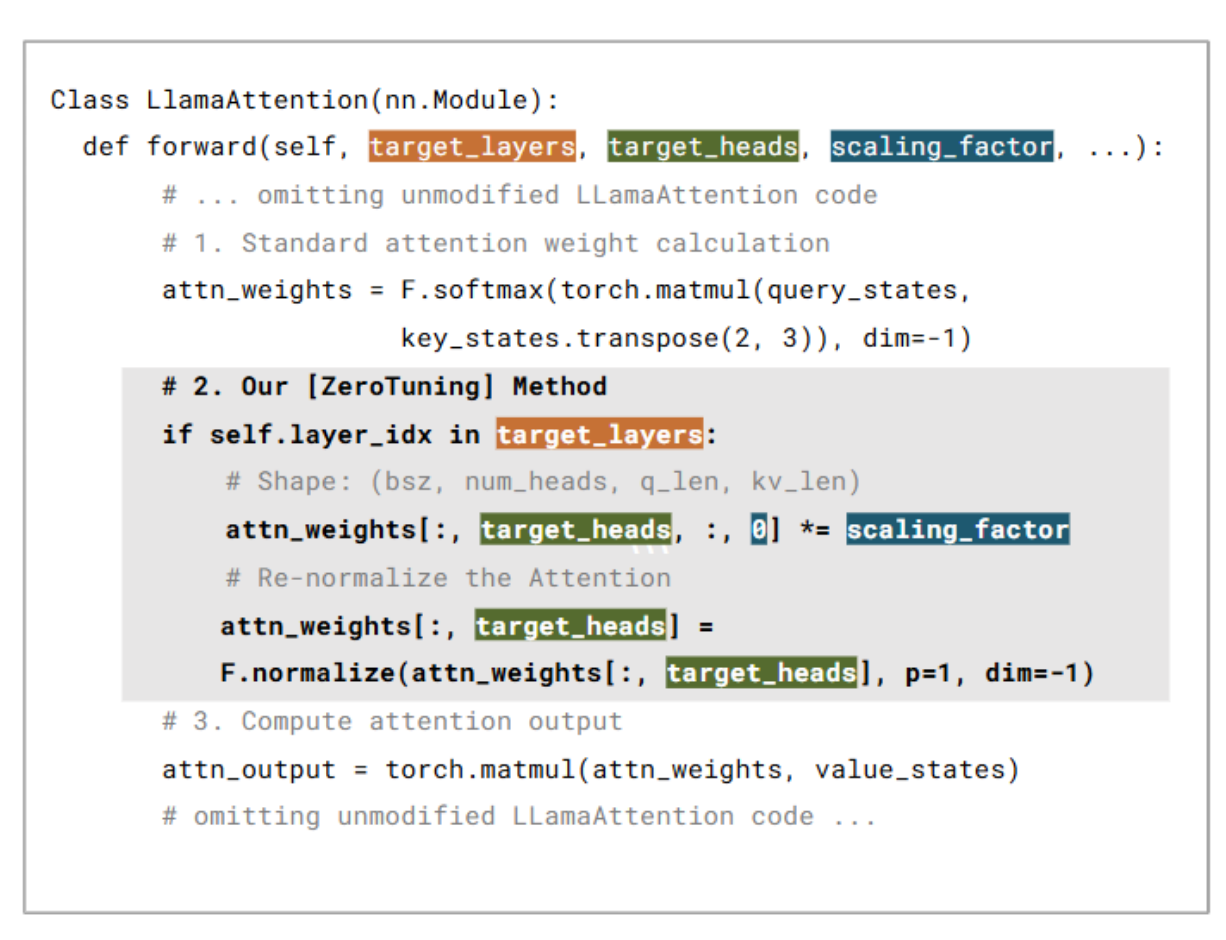
ZeroTuning: Unlocking the Initial Token’s Power to Enhance Large Language Models Without Training
Feijiang Han, Xiaodong Yu, Jianheng Tang, Delip Rao, Weihua Du, Lyle Ungar
Paper | Code & Demo | Blog | Poster
Key Points:
- Novel training-free optimization via initial token attention steering, supporting both supervised and unsupervised calibrations
- Lightweight implementation (four lines of code modification) achieves substantial gains: 19.9% on classification, 4.5% on QA, and 2.1% on multi-turn dialogue
- Explains why this method works through: (1) theoretical analysis; (2) output entropy and accuracy analysis; (3) error pattern analysis; (4) fine-grained layer/head analysis

Read Before You Think: Mitigating LLM Comprehension Failures with Step-by-Step Reading
Feijiang Han, Hengtao Cui, Licheng Guo, Zelong Wang, Zhiyuan Lyu
Key Points:
- Explained the effectiveness of prompt repetition through the lens of Attention: it helps models suppress focus on low-semantic tokens (e.g., punctuation) and redistribute attention to critical information.
- Identified Semantic Misunderstanding as a core reasoning bottleneck that persists even with CoT, stemming from the inherent constraints of the unidirectional attention mechanism.
- Proposed a training-free framework to resolve these issues by: (1) applying step-by-step reading logic, (2) automatically steering attention to key tokens via self-reference, and (3) resolving backward dependencies through iterative re-contextualization.
🔍 Research Interest 2: Model Adaptation
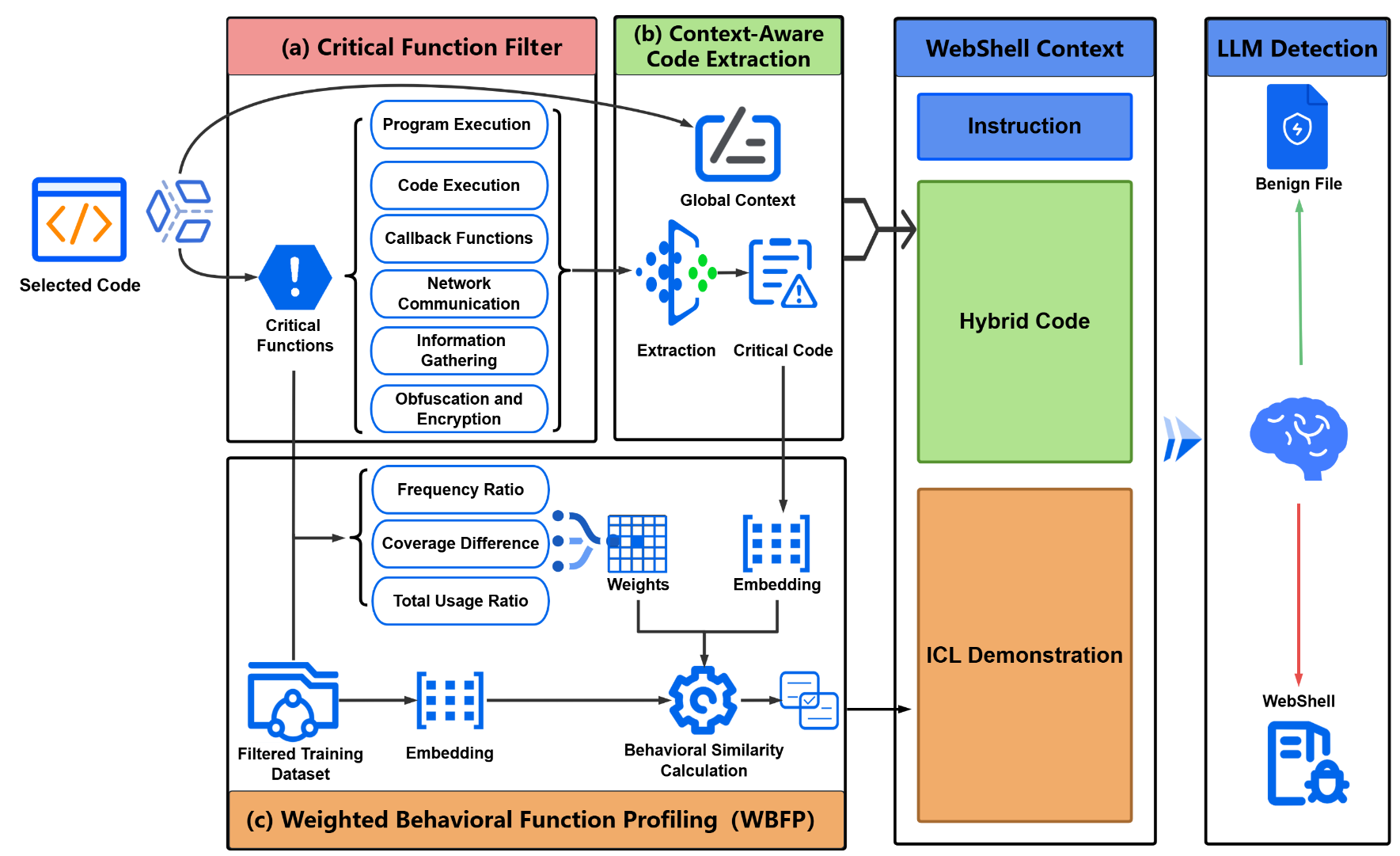
Feijiang Han, Jiaming Zhang, Chuyi Deng, Jianheng Tang, Yunhuai Liu
Key Points:
- First comprehensive study of LLMs’ capabilities in WebShell detection
- Novel BFAD framework improves LLM detection by 13.82% through function-aware analysis
- Enables both large and small LLMs to outperform traditional SOTA methods
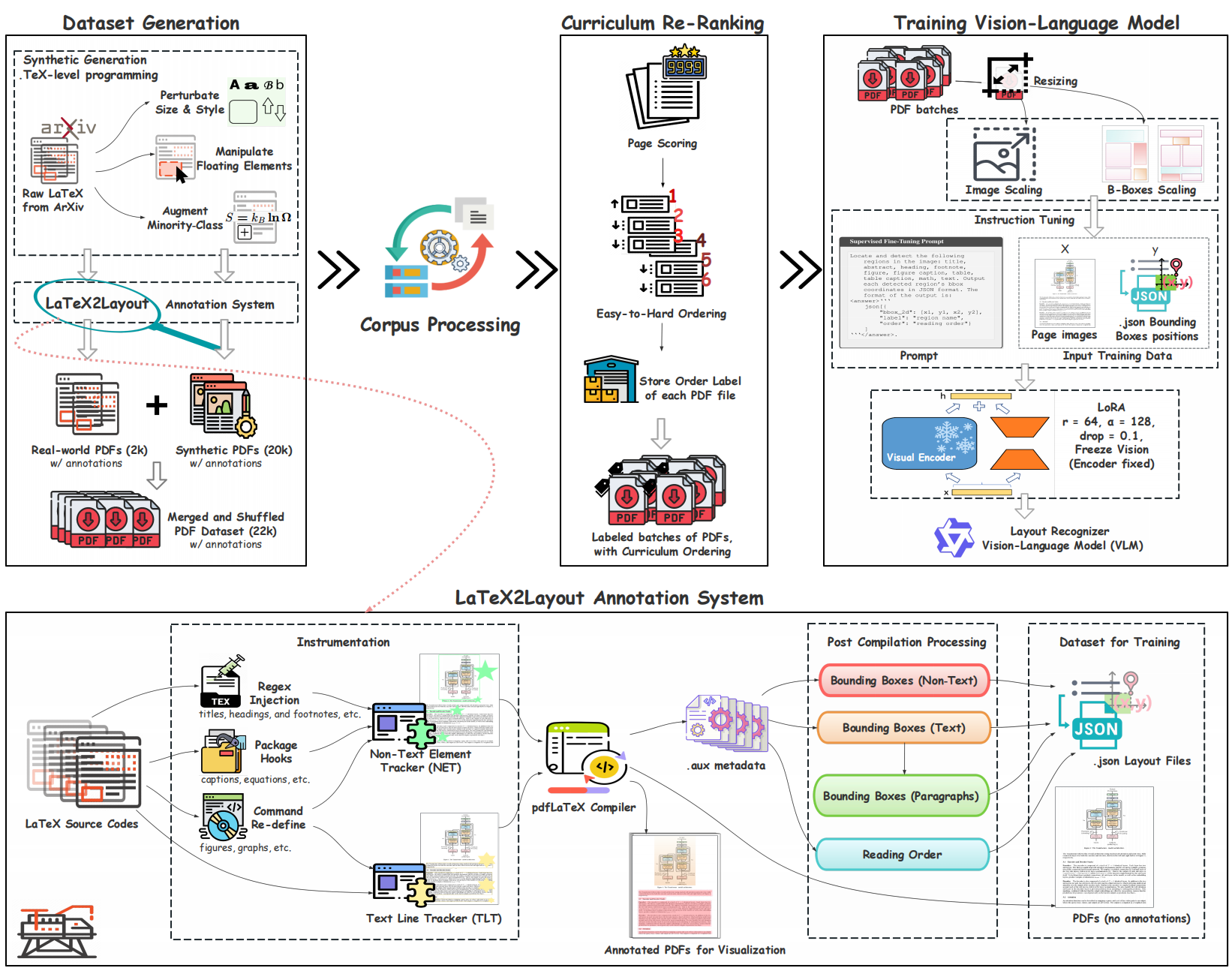
LaTeX2Layout: High-Fidelity, Scalable Document Layout Annotation Pipeline for Layout Detection
Feijiang Han, Zelong Wang, Bowen Wang, Xinxin Liu, Skyler Cheung, Delip Rao, Chris Callison-Burch, Lyle Ungar
[Paper] (Release Due: 2026.2.1) | [Code & Dataset] (Release Due: 2026.3.1)
Key Points:
- Novel pipeline extracting PDF layout information directly from LaTeX compilation (
No Human annotations and PDF Parsers) - Custom LaTeX packages for precise element tracking and accurate layout extraction
- 200% relative improvement over zero-shot baselines through curriculum learning and synthetic data augmentation
Feijiang Han
Paper | Video (AI) | Slide (AI) | [Code & Dataset] (Release Due: 2026.3.1)
Key Points:
- First systematic study automating WebShell family classification through representation learning
- Novel dynamic function call trace extraction and LLM-based synthetic trace generation for behavioral analysis
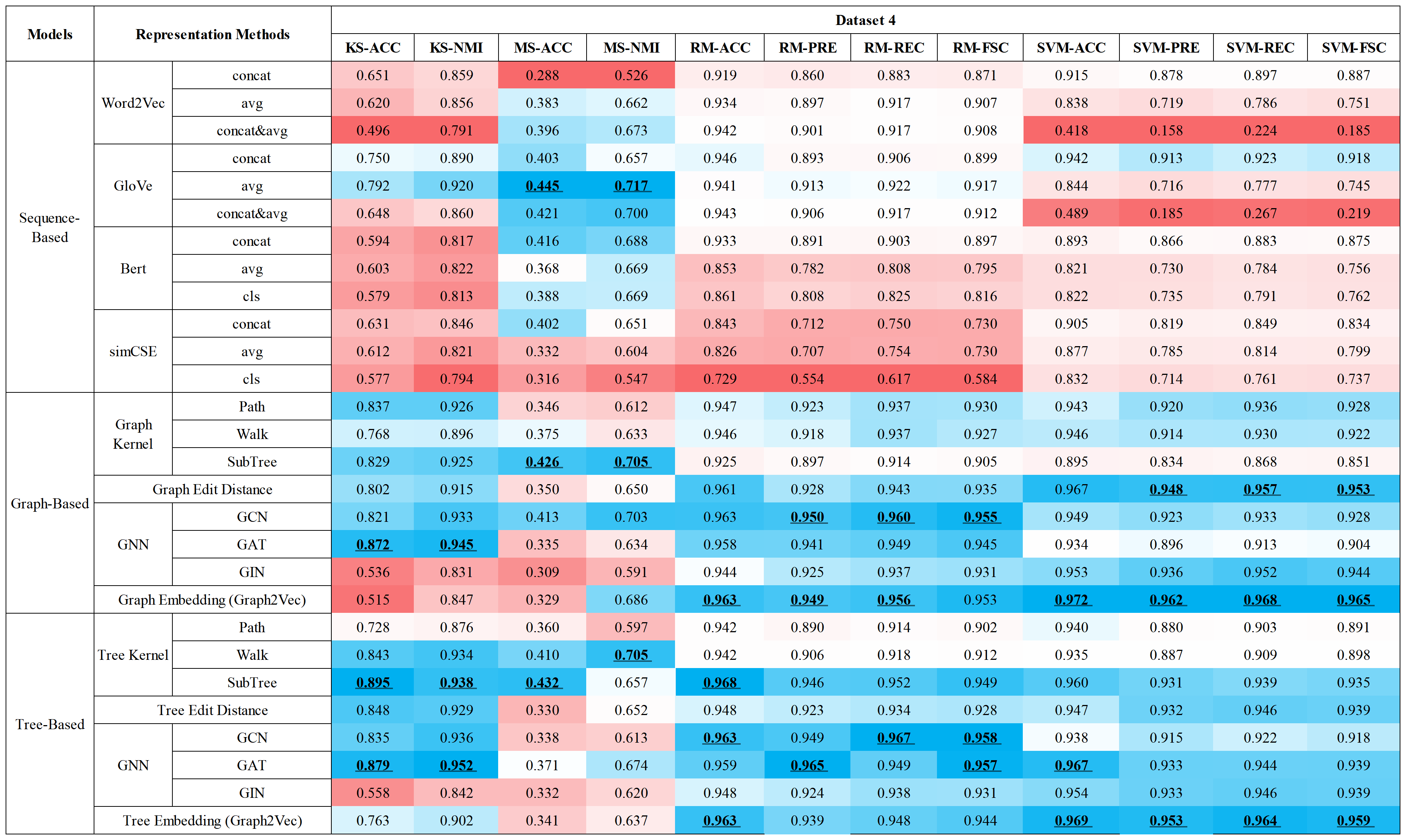
- Comprehensive evaluation of representation methods (sequence, graph, and tree-based models) across multiple datasets with practical insights for optimal model selection

ThinknCheck: Grounded Claim Verification with Compact, Reasoning-Driven, and Interpretable Models
Delip Rao, Feijiang Han, Chris Callison-Burch
Poster | [Paper] (Coming Soon)
Key Points:
- 1B-scale, 4-bit ThinknCheck verifier trained to “reason first, then decide” for scientific claim verification
- New reasoning-augmented datasets LLMAggreFact-Think and GSMClaims for document-grounded scientific and arithmetic claims
- Small model matches or surpasses larger specialized verifiers (e.g., MiniCheck-7B) while providing short, interpretable rationales
🌟 Research Interest 3: Other Topics (HCI, Big Data Visualization, IoT, Federated and Continual Learning)
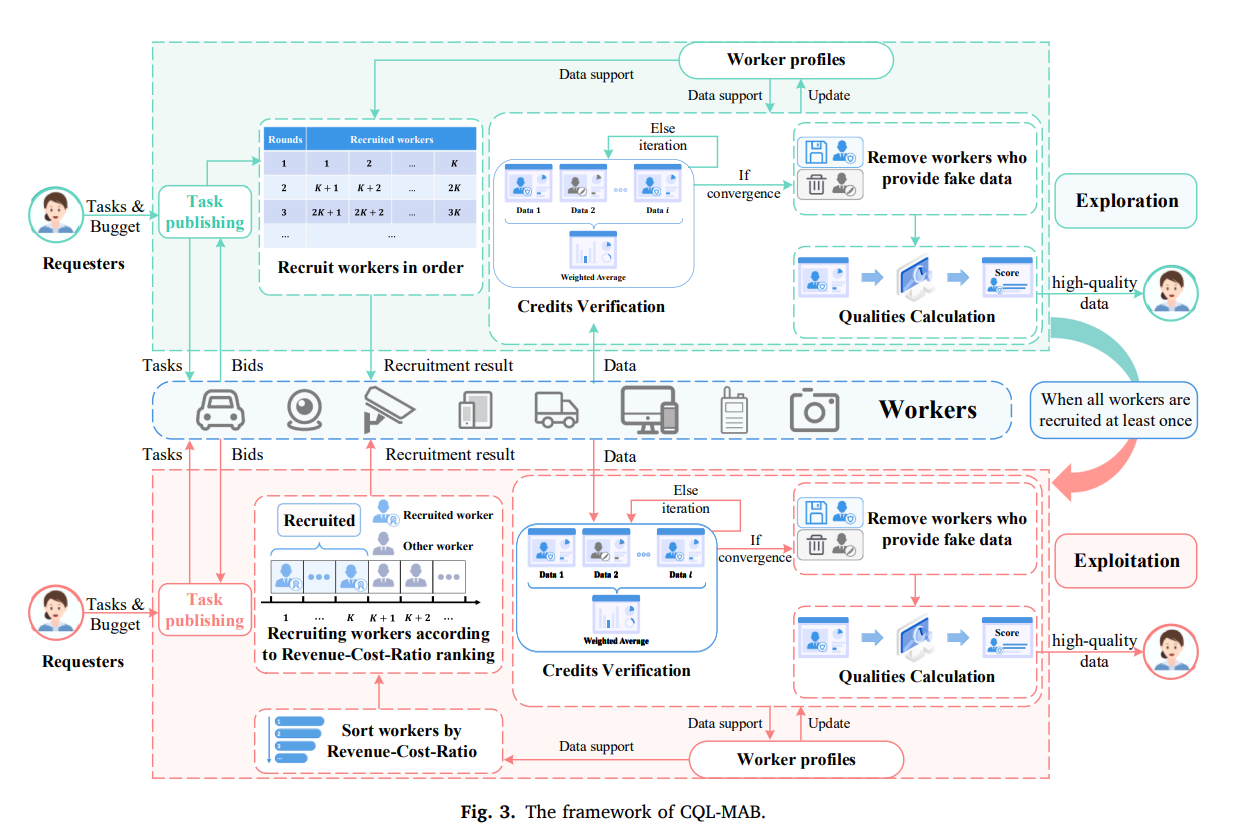
Credit and quality intelligent learning based multi-armed bandit scheme for unknown worker selection in multimedia MCS
Jianheng Tang, Feijiang Han, Kejia Fan, et al.
Key Points:
- Novel Credit and Quality Learning based Multi-Armed Bandit (CQL-MAB) scheme for solving the Post-Unknown Worker Recruitment problem in MCS
- Integrates credit identification and quality calculation for worker selection
- Theoretically proven truthfulness and efficiency in reverse auction settings
-
UBICOMP 2025CALM: A Ubiquitous Crowdsourced Analytic Learning Mechanism for Continual Service Construction with Data Privacy Preservation
Kejia Fan, Yuwei Huang, Jiayi He, Feijiang Han, Jianheng Tang, et al. -
arXiv 2025APFL: Analytic Personalized Federated Learning via Dual-Stream Least Squares
Kejia Fan, Jianheng Tang, Zixuan Yang, Feijiang Han, Jiayi Li, et al. -
arXiv 2025ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
Jianheng Tang, Haotian Zhuang, Dongxiao Fang, Jiayi Li, Feijiang Han, et al. -
Information Sciences 2024MAB-RP: A Multi-Armed Bandit based workers selection scheme for accurate data collection in crowdsensing
Yuwei Lou, Jianheng Tang, Feijiang Han, Anfeng Liu, et al. -
Information and Software Technology 2024Fctree: Visualization of function calls in execution
Fei Zhou, Yifan Fan, Shengchao Lv, Lingxiao Jiang, Zhuo Chen, Jingui Yuan, Feijiang Han, et al. -
IEEE IoT Journal 2023CRL-MABA: a completion rate learning-based accurate data collection scheme in large-scale energy internet
Kejia Fan, Jianheng Tang, Wenbin Xie, Feijiang Han, Yuwei Huang, et al. -
IEEE IoT Journal 2023BTV-CMAB: A bi-directional trust verification-based combinatorial multiarmed bandit scheme for mobile crowdsourcing
Jianheng Tang, Kejia Fan, Wenbin Xie, Feijiang Han, et al. -
Computer Communications 2023A Semi-supervised Sensing Rate Learning based CMAB scheme to combat COVID-19 by trustful data collection in the crowd
Jianheng Tang, Kejia Fan, Wenbin Xie, Lingxiao Zeng, Feijiang Han, et al.
🎖 Honors and Awards
- 2025 AAAI 2026 Scholarship
- 2025 COLM 2025 Registration & Travel Grant
- 2024 Xiaomi Special Scholarship (Top 10 university-wide)
- 2024 Outstanding Graduate of the Class of 2020
- 2023 National Scholarship for Outstanding Students
📝 Notes & Experiences
- Prompt Papers Are Dead: Embracing Scaling Training (Prompt论文已死,拥抱Scaling Training) - 从 Scaling 与 Training 视角讨论 Prompt 论文的局限与未来研究方向 (Chinese Version)
- 美国留学申请心得 - 我的美国留学申请经验总结与建议
📅 Schedule a Meeting
If you’d like to discuss research collaboration or have any questions, feel free to schedule a meeting with me:
If you feel our backgrounds align and you’d like to collaborate, get help, or seek mentorship, please fill out this short form: Collaboration Interest Form