
I am an incoming CS Ph.D. student at the University of Maryland  , where I will be advised by Prof. Furong Huang. I received my master’s degree from the University of Pennsylvania
, where I will be advised by Prof. Furong Huang. I received my master’s degree from the University of Pennsylvania  , where I worked with Prof. Chris Callison-Burch, Prof. Lyle Ungar, Delip Rao, and Dr. Xiaodong Yu.
, where I worked with Prof. Chris Callison-Burch, Prof. Lyle Ungar, Delip Rao, and Dr. Xiaodong Yu.
Goal: Build mechanism-guided AI systems that can understand the world, improve themselves, and still remain understandable and controllable to people.
Research Interest: {LLMs, VLMs, VLAs, Cognitive Science}
Research Question: How can we more accurately understand models (e.g., how knowledge is stored, how training dynamics shape representations, how fine-tuning changes behavior, how attention, representations, and circuits interact)? Can these insights serve as first principles for designing better AI systems (e.g., better training, collaboration, and self-evolution)?
My work spans two complementary directions:
From understanding → to reliable impact → to continual improvement
-
1. Mechanism-driven Understanding and Optimization: I study the internals of LLMs and VLMs. I believe interpretability should help us optimize and control models, not just describe them after the fact. Recent work includes understanding why attention sinks emerge and how to exploit them (ZeroTuning, ICLR 2026), diagnosing comprehension failures through the lens of attention (SSR, ICASSP 2026), and building the first unified actionable framework for actionable MI (Locate, Steer, and Improve, ACL 2026).
(Why I care about interpretability) -
2. Model Adaptation and Alignment: I adapt foundation models into domain experts for settings where general models still struggle. Recent work includes the first fully LaTeX-derived layout annotation pipeline for large-scale document understanding (LaTeX2Layout, AAAI 2026), LLM-based systems for million-token malicious code analysis (WebShell Detection, COLM 2025; WebShell Classification, AAAI 2026), and efficient and effective verifier for scientific claim verification (ThinknCheck, NLDB 2026).
(Why I care about model adaptation)
I am also the co-founder of Savable Koupon AI, where we work on AI-powered price tracking, product analysis, and recommendation systems for e-commerce. I also serve as a reviewer for conferences including ICLR, ICML, ACL, CVPR, COLM, and AAAI.
I enjoy mentoring undergraduate and master’s students on research projects. I also offer free guidance to Chinese students applying to master’s and PhD programs in the US — feel free to check out my Xiaohongshu where I share application tips and research advice.
Feel free to reach out for collaboration or just to say hi. Email me at feijianghan [at] gmail [dot] com (it’s — for me right now).
🔥 News
- April 2026: 🏅 Honored to receive the Outstanding Research Award from the University of Pennsylvania!
- April 2026: 🎉 ACL 2026 x 1
- March 2026: 🎉 NLDB 2026 x 1
- March 2026: 🎉 I will be starting my PhD journey in Computer Science!
- January 2026: 🎉 ICLR 2026 x 2
- January 2026: 🎉 ICASSP 2026
- November 2025: 🎉 AAAI 2026 x 2
- July 2025: 🎉 COLM 2025
- June 2025: 🎉 Paper published in Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) 2025
- June 2025: 🎉 MOSS@ICML2025
Why I’m excited about these problems
Why I care about interpretability
TLDR: I care about explanations because they can do two things: (1) help us trust models in practice, (2) help us design better models without relying only on trial and error.
For me, interpretability starts with curiosity. I like looking at a model and asking: why did that happen?
There is a small joy in that moment. It feels a bit like watching insects as a kid. You stare for long enough, something weird happens, and suddenly there is a pattern you did not see before.
More practically, interpretability also serves a long-term goal: building AI systems that are genuinely reliable, possibly all the way to AGI or even ASI.
- If scaling eventually leads to AGI, we may get extremely capable black-box systems. Then the key question becomes safety and alignment. How do we ensure a superintelligent model consistently acts in good faith and does not quietly deceive people or cause harm?
- If scaling alone is not enough, interpretability becomes a scientific problem. Why do these models work at all? What actually drives their behavior? Which parts come from data, architecture, training dynamics, or post-training?
I often think about how physics matured. First came careful observations (Tycho Brahe). Then hypotheses (Kepler). Then principles (Newton). AI has made huge empirical progress, and I really like the current mechanistic interpretability line of work: logit lens analyses, sparse autoencoders, circuit discovery, and the recent work from Anthropic. But we are still far from that Newton stage.
The questions I want to ask are closer to training dynamics and model architecture. Why do compositional features and circuits appear after training? Why do we sometimes see sparsity, low-rank structure, or cleanly separated factors inside a model? Can we explain these outcomes from gradient-based learning, instead of only opening the model after training and collecting evidence?
This is why I like papers such as Learning Dynamics of LLM Finetuning and Why DPO is a Misspecified Estimator and How to Fix It. They try to explain concrete failure modes in post-training, such as why SFT can increase hallucination and why DPO can degrade over time.
My hope is that interpretability can slowly move from biology-style observation to physics-style reasoning. In the near term, I care most about making interpretability actionable. A good explanation should help us localize the issue, steer the behavior, and improve the model.
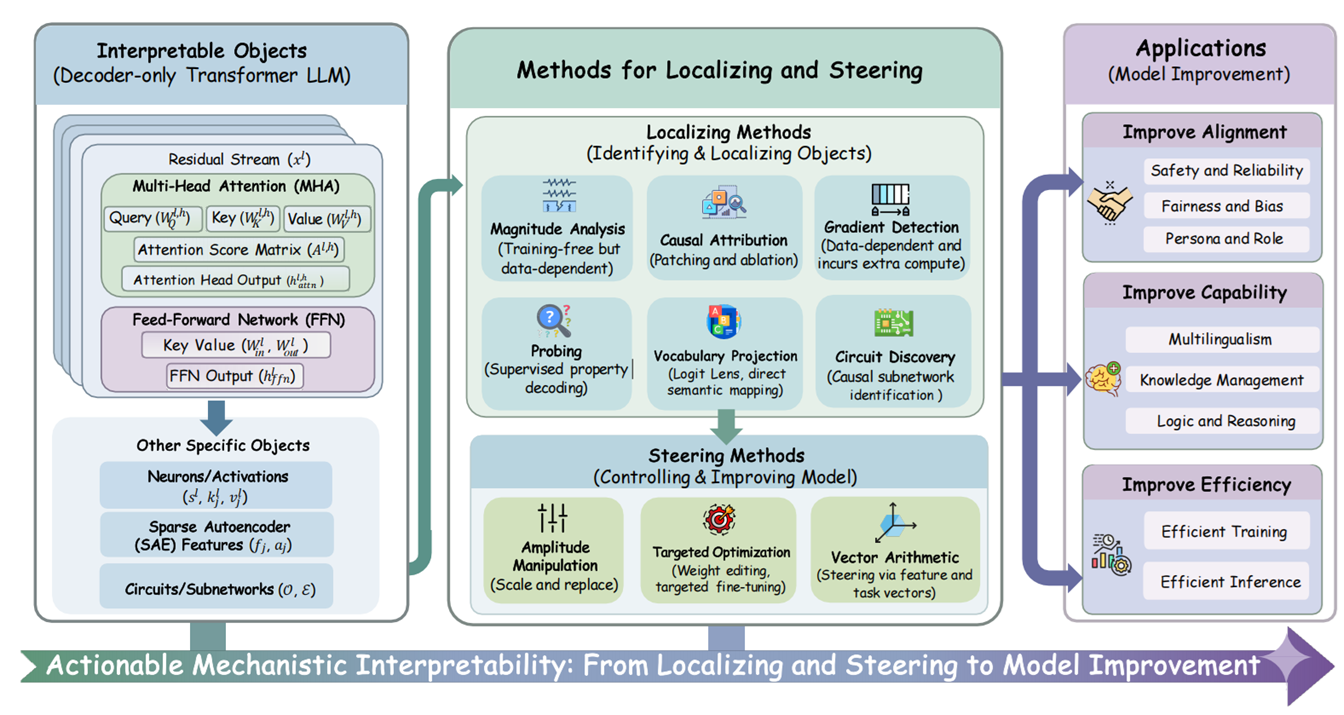
Actionable Mechanistic Interpretability: From Localizing and Steering to Model Improvement
(Figure from the survey "Locate, Steer, and Improve: A Practical Survey of Actionable Mechanistic Interpretability in Large Language Models")
Why I care about model adaptation
The other question I keep coming back to is adaptation.
Scaling has worked, but the returns may slow down. It is unlikely that every new GPT-n will feel as dramatic as earlier leaps. At the same time, we have already had LLMs in the real world for several years, yet there are still many specialized tasks they cannot do well. Pretraining will never perfectly cover every niche, workflow, or kind of expertise.
So I care about a practical question: how do we turn a strong base model into a system that is actually useful for a specific need?
I think about this in two layers, as illustrated below:
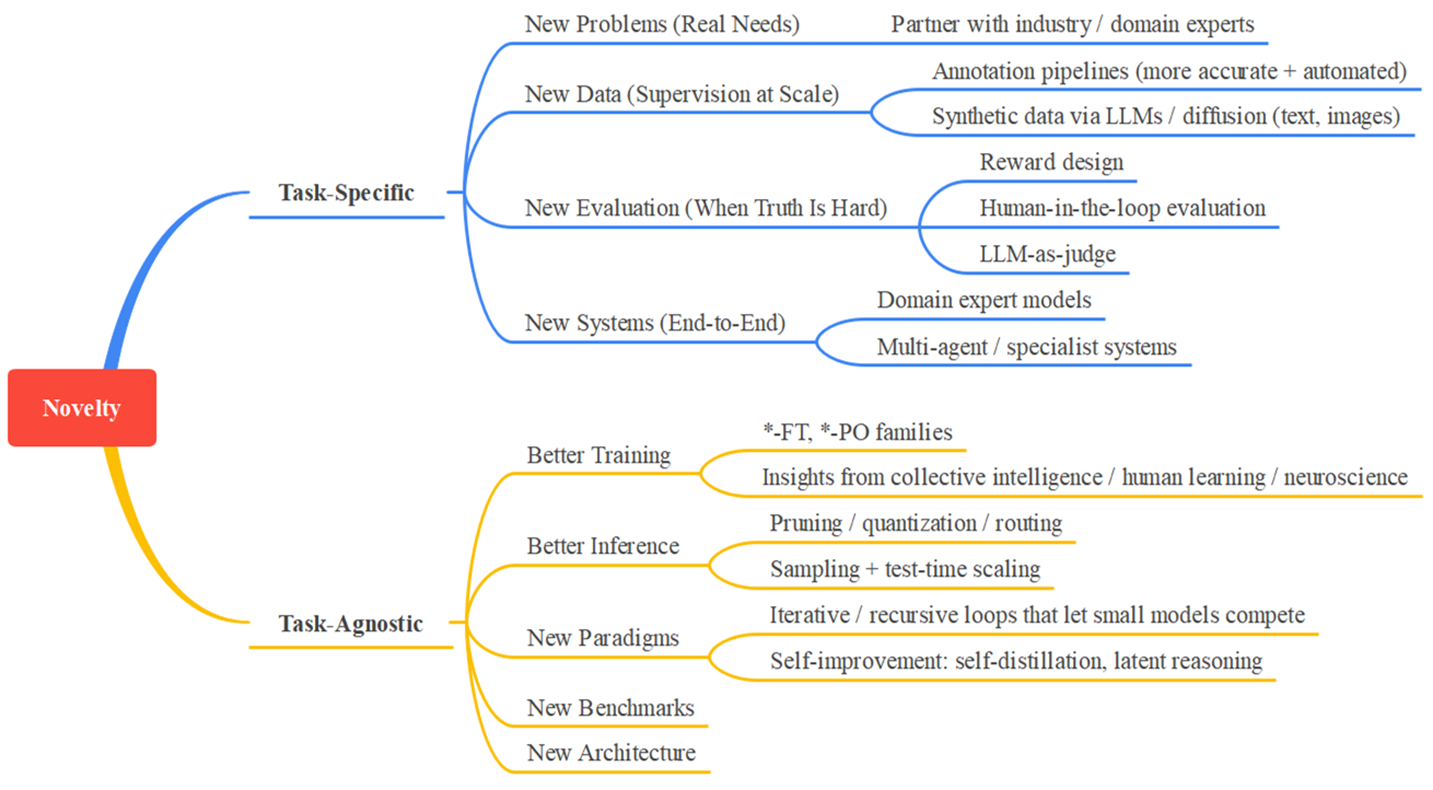
Novelty in Model Adaptation: Task-Specific vs Task-Agnostic Approaches
The first layer is the general adaptation pipeline. Rich Sutton’s The Bitter Lesson still feels relevant in the LLM era: methods that make good use of compute, search, and learning tend to win over hand-crafted priors. With that in mind, I want to improve the task-agnostic pipeline. That includes post-training methods like SFT, RL, and distillation; inference efficiency methods such as quantization, pruning, layer skipping, and routing; and system components like retrieval, evaluation, and benchmarks, because the workflow around a model often matters as much as the model itself. As these external workflows (aka ‘Harness’) become more important, I am also increasingly interested in agent systems.
The second layer is taking these tools into real domains and making them work end to end. This idea is not new. It was already important in the BERT era, and it is still important now. Beyond popular areas like coding and document understanding, I think many domains that depend on careful human judgment could benefit from LLM-based specialists. Malware and virus detection are good examples.
Some people see this direction as just engineering because it often starts with data, training, and systems. I am drawn to it because I believe that kind of engineering can carry real scientific novelty.
Sometimes the novelty lies in how you get data when data is scarce. Sometimes it lies in how you design synthetic data that teaches the right behavior. Sometimes it lies in how you change representations or architectures when the base model cannot capture a key dependency. Sometimes it lies in how a new industrial need becomes a new research question.
In the long run, I am optimistic about a system view of intelligence. Instead of relying only on one monolithic model, we may build many strong and efficient specialists, then let them collaborate. That kind of system could be easier to adapt, easier to maintain, and easier to inspect.
📝 Selected Publications
For a complete list of publications, please visit my Google Scholar
🔮 Research Interest 1: Actionable Mechanistic Interpretability in Large Language Models
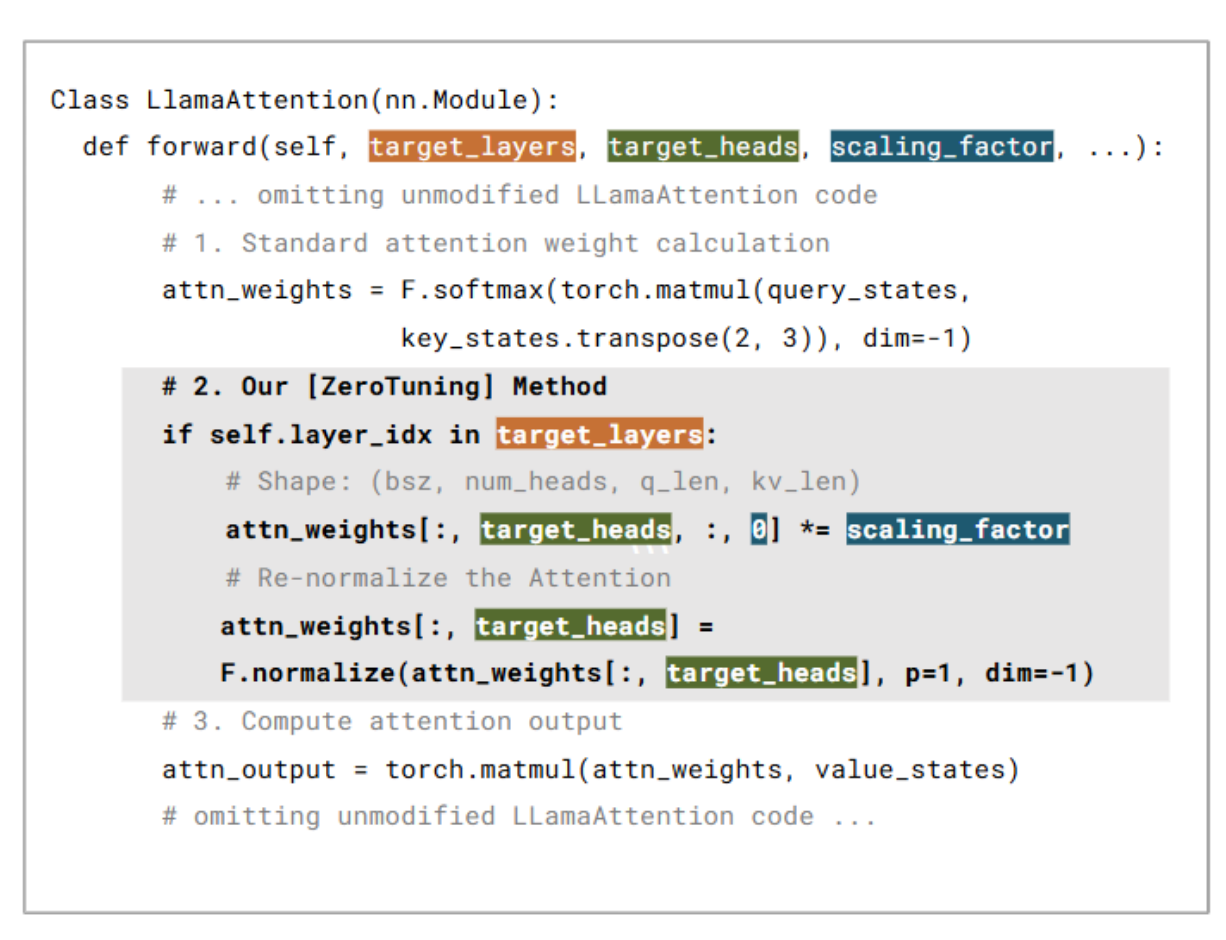
ZeroTuning: Unlocking the Initial Token’s Power to Enhance Large Language Models Without Training
Feijiang Han, Xiaodong Yu, Jianheng Tang, Delip Rao, Weihua Du, Lyle Ungar
Paper | Code & Demo | Blog | Poster | ICLR Talks
TL;DR. Token-level attention steering can boost frozen LLMs, but prior methods often depend on fragile heuristics to find “important” task tokens. ZeroTuning shows a simpler universal control lever: tune only the initial token (e.g., <BOS>). With tiny head-specific biases on BOS attention logits, we can reshape downstream attention (sharpen/flatten), lower output entropy, and unlock pretrained knowledge—without any parameter updates.
Hengyuan Zhang, Zhihao Zhang, Mingyang Wang, Zunhai Su, Yiwei Wang, Qianli Wang, Shuzhou Yuan, Ercong Nie, Xufeng Duan, Feijiang Han, Qibo Xue, Zeping Yu, Chenming Shang, Xiao Liang, Jing Xiong, Hui Shen, Chaofan Tao, Zhengwu Liu, Senjie Jin, Zhiheng Xi, Dongdong Zhang, Sophia Ananiadou, Tao Gui, Ruobing Xie, Hayden Kwok-Hay So, Hinrich Schütze, Xuanjing Huang, Qi Zhang, Ngai Wong
TL;DR. This survey reframes mechanistic interpretability as an actionable pipeline, not just a diagnostic tool: first locate where behaviors live, then steer those components, and finally use the intervention to improve alignment, capability, and efficiency in LLMs.

Read Before You Think: Mitigating LLM Comprehension Failures with Step-by-Step Reading
Feijiang Han, Hengtao Cui, Licheng Guo, Zelong Wang, Zhiyuan Lyu
TL;DR. Many “reasoning” failures in LLMs are actually comprehension failures—the model misreads the question (semantic misunderstanding), so even Chain-of-Thought can’t reliably help. We introduce Step-by-Step Reading (SSR), a training-free framework that makes models read before they think: parse the question incrementally, keep each reasoning step grounded to the text, and fix backward dependencies via iterative re-contextualization.
🔍 Research Interest 2: Model Adaptation
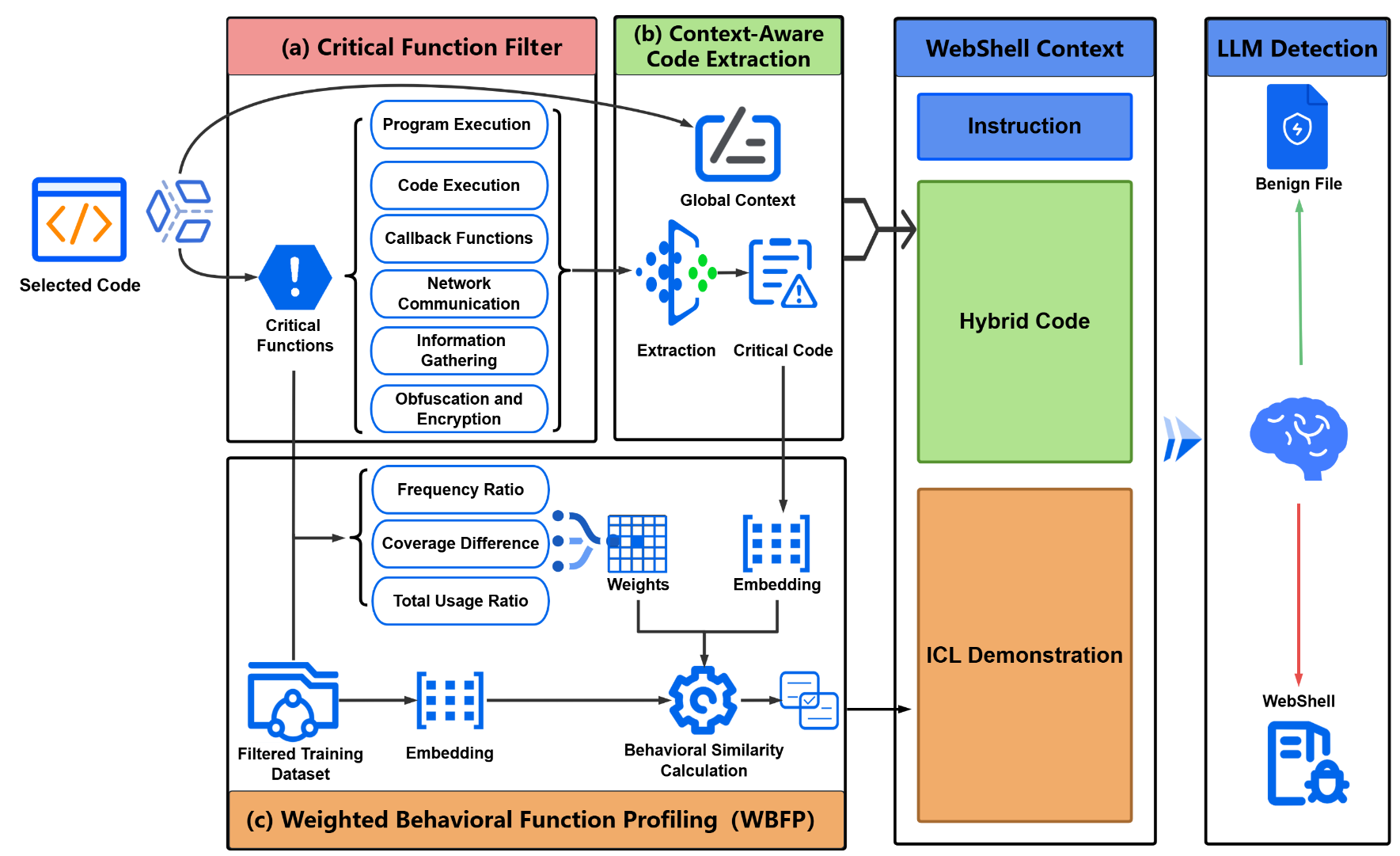
Feijiang Han, Jiaming Zhang, Chuyi Deng, Jianheng Tang, Yunhuai Liu
Paper | Resources | Blog | Poster
TL;DR. WebShell detection is hard for LLMs because a server-side script can span millions of tokens while the truly malicious logic is often just a tiny, obfuscated fragment—so naïvely feeding the whole file dilutes the signal and breaks context limits. We provide the first comprehensive evaluation of LLMs for WebShell detection and introduce BFAD, a behavior-driven, function-aware pipeline that helps LLMs focus on the most indicative code, yielding a +13.82% average F1 improvement and pushing both large and small LLMs toward (or beyond) prior SOTA.
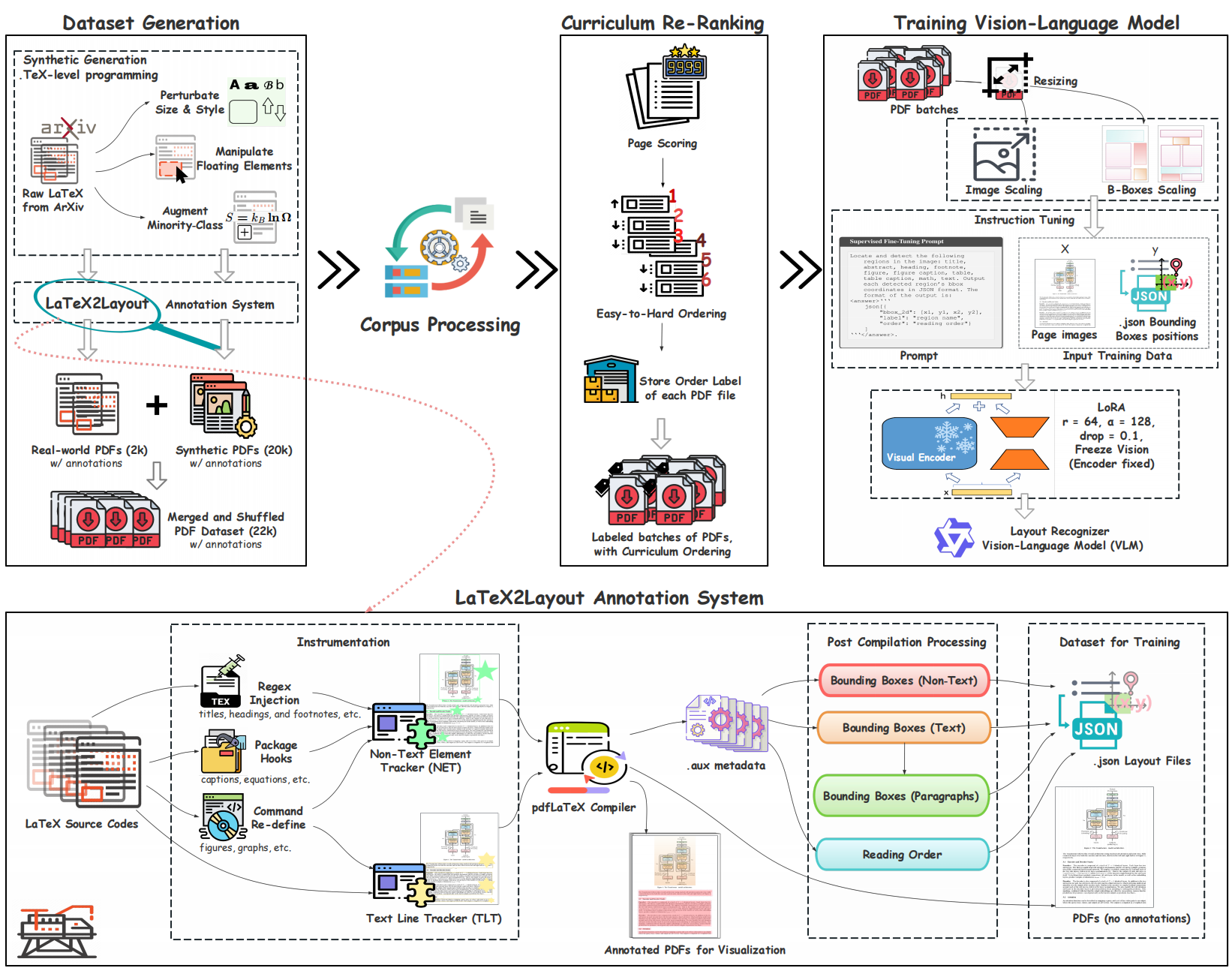
LaTeX2Layout: High-Fidelity, Scalable Document Layout Annotation Pipeline for Layout Detection
Feijiang Han, Zelong Wang, Bowen Wang, Xinxin Liu, Skyler Cheung, Delip Rao, Chris Callison-Burch, Lyle Ungar
TL;DR. Layout detection turns a PDF into structured page understanding (bounding boxes + reading order), but current VLMs struggle mainly because high-fidelity supervision is scarce and PDF-parser-based labels are noisy and expensive. We introduce LaTeX2Layout, a scalable data-centric pipeline that extracts pixel-accurate layout ground truth directly from the LaTeX compilation process, enabling large-scale training without manual annotation.
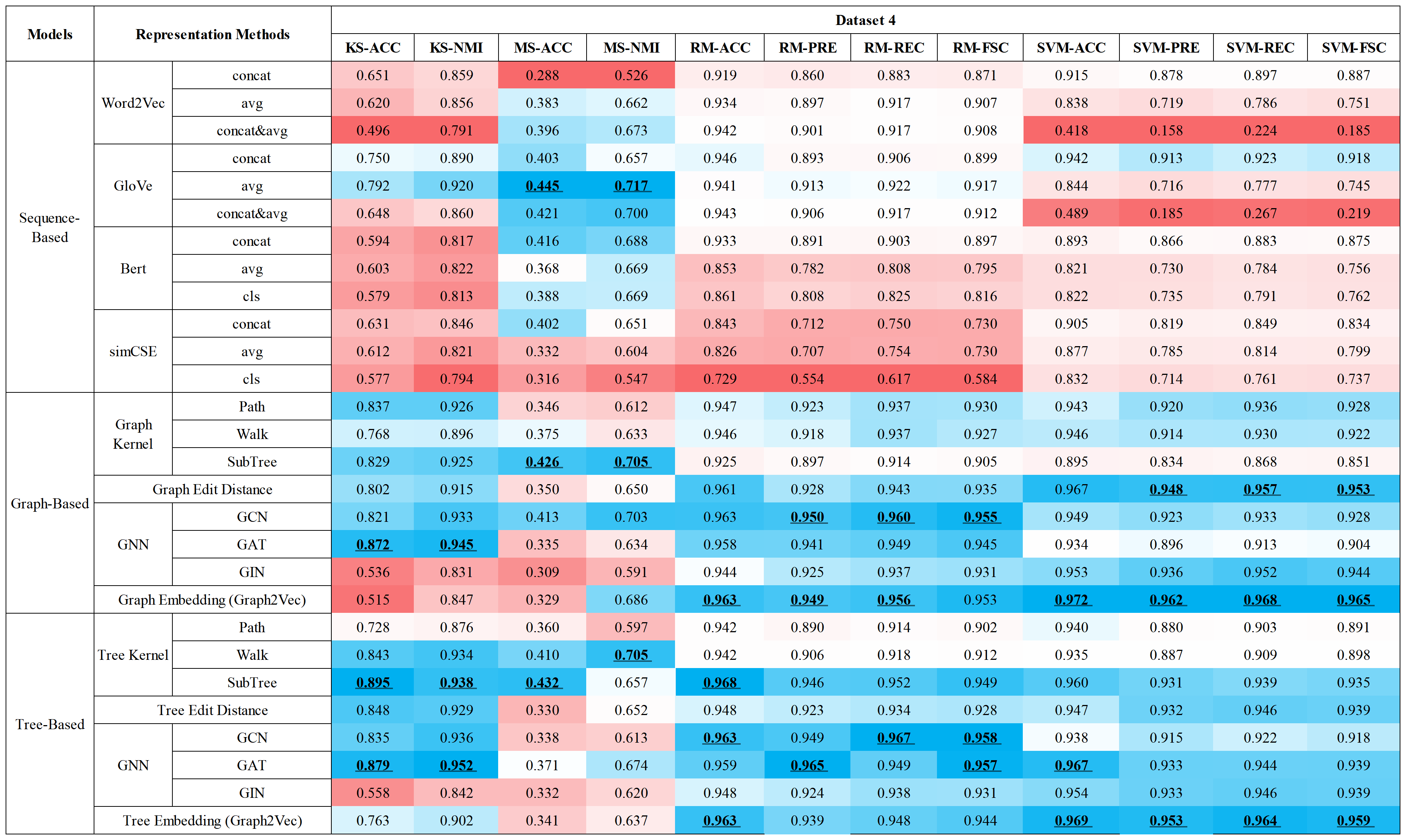
Feijiang Han
Paper | Video (AI) | Slide (AI) | [Code & Dataset]
TL;DR. While WebShell detection answers “malicious or not,” real-world defense also needs attribution and tracking: WebShells come in diverse families with different behaviors and variants. We are the first to systematically study representation learning for automated WebShell family classification.

ThinknCheck: Grounded Claim Verification with Compact, Reasoning-Driven, and Interpretable Models
Delip Rao, Feijiang Han, Chris Callison-Burch
TL;DR. Efficient scientific claim verification is essential for trustworthy literature review and retrieval—but most strong verifiers are large, expensive, and hard to interpret. We develop ThinknCheck, a compact “reason first, then decide” verifier, and summarize best practices for making small LLMs reliable and interpretable on document-grounded claim verification.
🌟 Earlier Work: Crowdsourcing, Federated & Continual Learning, HCI
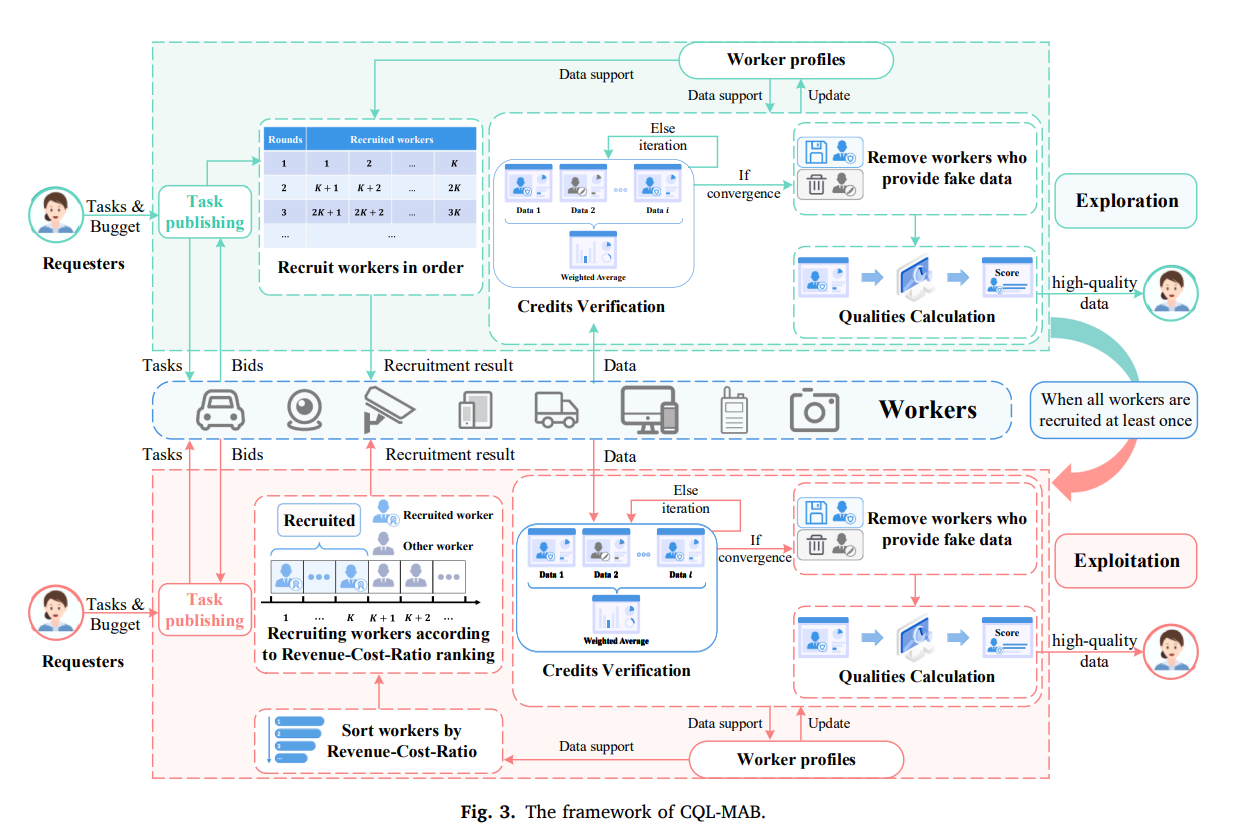
Credit and quality intelligent learning based multi-armed bandit scheme for unknown worker selection in multimedia MCS
Jianheng Tang, Feijiang Han, Kejia Fan, et al.
TL;DR. High-quality training data is the bottleneck for modern multimodal and foundation models, and mobile crowd sensing (MCS) is a scalable way to collect it—but platforms must recruit workers before knowing who is trustworthy or produces high-quality data. We formulate this as an online decision-making problem under uncertainty and propose CQL-MAB, a bandit-style RL scheme that learns workers’ credit (honesty) and quality (data utility) from feedback and selects workers cost-effectively with incentive guarantees.
-
UBICOMP 2025CALM: A Ubiquitous Crowdsourced Analytic Learning Mechanism for Continual Service Construction with Data Privacy Preservation
Kejia Fan, Yuwei Huang, Jiayi He, Feijiang Han, Jianheng Tang, et al. -
arXiv 2025APFL: Analytic Personalized Federated Learning via Dual-Stream Least Squares
Kejia Fan, Jianheng Tang, Zixuan Yang, Feijiang Han, Jiayi Li, et al. -
arXiv 2025ACU: Analytic Continual Unlearning for Efficient and Exact Forgetting with Privacy Preservation
Jianheng Tang, Haotian Zhuang, Dongxiao Fang, Jiayi Li, Feijiang Han, et al. -
Information Sciences 2024MAB-RP: A Multi-Armed Bandit based workers selection scheme for accurate data collection in crowdsensing
Yuwei Lou, Jianheng Tang, Feijiang Han, Anfeng Liu, et al. -
Information and Software Technology 2024Fctree: Visualization of function calls in execution
Fei Zhou, Yifan Fan, Shengchao Lv, Lingxiao Jiang, Zhuo Chen, Jingui Yuan, Feijiang Han, et al. -
IEEE IoT Journal 2023CRL-MABA: a completion rate learning-based accurate data collection scheme in large-scale energy internet
Kejia Fan, Jianheng Tang, Wenbin Xie, Feijiang Han, Yuwei Huang, et al. -
IEEE IoT Journal 2023BTV-CMAB: A bi-directional trust verification-based combinatorial multiarmed bandit scheme for mobile crowdsourcing
Jianheng Tang, Kejia Fan, Wenbin Xie, Feijiang Han, et al. -
Computer Communications 2023A Semi-supervised Sensing Rate Learning based CMAB scheme to combat COVID-19 by trustful data collection in the crowd
Jianheng Tang, Kejia Fan, Wenbin Xie, Lingxiao Zeng, Feijiang Han, et al.
🎖 Honors and Awards
- 2026 Upenn Outstanding Research Award
- 2025 AAAI 2026 Scholarship
- 2025 COLM 2025 Registration & Travel Grant
- 2024 Xiaomi Special Scholarship (Top 10 university-wide)
- 2024 Outstanding Graduate of the Class of 2020
- 2023 National Scholarship for Outstanding Students
📝 Notes & Experiences
- Where do AI models agree — and disagree — on the world’s top CS schools? - We asked 11 leading large language models to rank the top 50 computer science universities worldwide, using only their internal knowledge and intuition. Here’s what they said.
- A Comprehensive Guide to the Computer Science PhD Journey: A Survey of Collected Wisdom - This survey distills hard-won CS PhD advice from nearly 20 well-known researchers’ essays and talks into one practical, end-to-end guide. It covers the full arc—from applying and choosing an advisor to building a sustainable research workflow, publishing effectively, and planning your post-PhD path.
- A curated list of Best Paper Award winners from top ML/NLP venues (ICLR, NeurIPS, ICML, ACL, EMNLP, NAACL, AAAI, and more), covering 2022–2026 - A resource for developing research taste.
- 美国留学申请心得 - 我的美国留学申请经验总结与建议 (Chinese Version)
📅 Collaboration
If you’d like to discuss research collaboration or have any questions, feel free to schedule a meeting with me:
If you feel our backgrounds align and you’d like to collaborate, get help, or seek mentorship, please fill out this short form: Collaboration Interest Form
Misc
Beyond research, I enjoy writing and sharing knowledge. I maintain a blog on Xiaohongshu where I share research experiences, lecture summaries, insights, and paper discussions. I find that writing helps me think more clearly and connect with others in the community.
I also practice traditional Chinese martial arts, including Tai Chi, and health qigong practices such as Mawangdui Daoyin. These practices help me maintain balance and focus, both physically and mentally.